[Table of Contents] |
[5. Design information management] |
[7. Case Study: Design system for high-level synthesis] |
[Table of Contents] |
[5. Design information management] |
[7. Case Study: Design system for high-level synthesis] |
| language | mostly used for ... |
|---|---|
| VHDL | behavioural and structural descriptions on algorithm and functional block levels |
| Verilog | behavioural and structural descriptions on register transfer and gate levels |
| EDIF | netlists and graphical data for schematics and physical layout |
| GDS-II | graphical data for physical layout |
| C++ | behavioural descriptions on algorithm level |
| Prolog | behavioural descriptions on architecture and algorithm levels |
This diversity of languages in design use implies that vendors of EDA frameworks make an arbitrary selection of the languages they want to support, mainly based on customer demands. As design methodologies are different from company to company and also evolve constantly, a framework vendor continuously has to support new design description languages. He may quickly be in a position in which supporting new languages(1) based on customer demands forms a major part of the overall effort put into framework development. There are three viable approaches to solve this problem:
Traditionally, writing language processors is accomplished by any of the following alternatives:
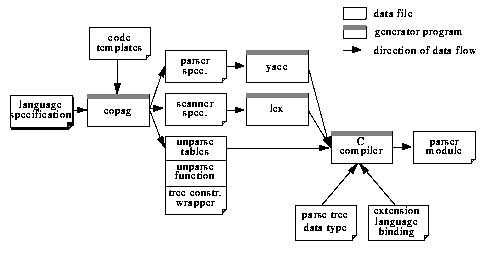
The choice of standard compiler construction tools like yacc and lex suggests that the processing of design files is very similar to the initial parsing phase of a compiler for a particular design description language. There are, however, significant differences:
The existence of component configurations in a design hierarchy complicates matters. In cases where a design description language is used that supports configurations (like VHDL), the configurations managed by the DIM service can be translated into appropriate configuration declarations in the language and emitted along with the selected interfaces and implementations. If, however, the design language does not have a notion of "configuration" or the notion supported by the language grossly deviates from the notion used by the DIM service, configurations have to be resolved and emitted as static bindings between compound implementations and their components.
As stated earlier, we can assume that only little information out of the whole information content of a design file is needed for successful design information management. We can furthermore assume design files to be syntactically correct. These two assumptions greatly simplify the amount of syntax that actually has to be specified exactly. On the other hand, partial analysis poses additional problems not normally encountered in syntax analysis. While large parts of a design file can be analysed according to a lexical and syntactical specification that generously ignores most of the tedious detail of a complete design description, other parts have to be analysed down to single lexems in order to retrieve all the information necessary for design information management. For example, the analysis of a VHDL file only has to reveal the names and extent of contained entity declarations and architecture bodies, but all the information specified in a configuration declaration has to be retrieved.
We solve this problem by allowing modular language specifications. The specification of a design description language may consist of several modules, each of which defines the lexical properties and syntax for a part of the whole language. There is always a main module that provides an entry point for syntax analysis and generation. With the recognition of certain constructs, another module may be invoked that takes over syntax analysis from where it was invoked. Once a complete program defined by the language of the subordinate module has been recognized, control is returned to the caller. As different modules can define completely different lexical properties, modular language specifications allow to analyse design files at varying granularities. The net result is a major reduction in the amount of language detail that has to be specified for design file analysis while we are still able to digest fine-grained detail where appropriate.
We use the same language specification to define both input and output. As such, the specification language needs to define both lexical properties and syntax in one place. In addition, grammar symbols may be tagged for ease of reference during import and export. The specification may be decorated with output formatting information.
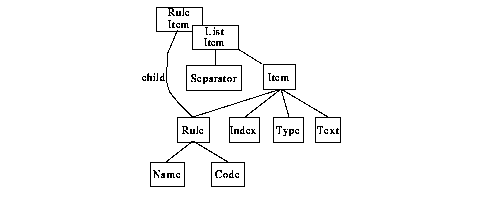
We provide no operations to prune the automatically created parse trees, because there is little need for this extra complexity. With modular language specifications, parse trees proved to be small compared to those created from complete fine-grained syntax analysis. Parse trees directly reflect the extended BNF by which the syntax is specified. Tree nodes that stem from certain syntax rules carry the name of this rule as their type. Lists, possibly with separators like "," or ";", create dedicated list nodes. Text ranges that are parsed by nested specification modules result in sub-trees.
We prefer the programmed approach to the more descriptive approach of statically linking language constructs to DIM object types because thus
With this association in place, export of a DIM object into a valid design file is a matter of selecting the object and invoking its unparse method. The unparse method creates a parse tree with constant text in the right places and variables filled from the DIM database. Only a simple preorder traversal is needed to transform such a tree into a stream of text in the desired syntax.
Now that we have outlined our approach, we will present the technical realization of this new framework service in Sections 6.4 through 6.6, use VHDL as a case study in Section 6.7 and compare our approach with existing work in Section 6.8.
As a rule, the generated parser modules assume that they process syntactically correct design files. They therefore read over lexems that are not explicitly defined in the language specification. This behaviour can be exploited to simplify the language specification: Only those languages elements have to be defined that either carry valuable information for design information management or those that are necessary to recognize the syntactical structure of a design description. All other text will be ignored by syntax analysis but will nevertheless appear as text attributes in the parse tree to ensure that no information is lost for later export.
When the subordinate parser has recognized a valid text in the language that it defines, it returns the control back to the invoking parser.
rule rule {
"rule" ID opt { "-syntax" } alternatives
}
 |
There are two variants of the parse function:
Tree* parse (char* fileName);
Tree* parse (Tree* parent);
While the first variant is invoked directly from the extension language binding to create a parse tree of the named file, the second variant is used to pass control to a subordinate parsing module. The unparse function has the following signature:
Tree* unparse (char* rule, ...);
The first parameter always denotes the syntax rule to be unparsed. The following parameters supply name/value pairs for variable parts in a derivation of the named rule. We will explain the wrapper function to create parse trees when we describe the extension language binding to parser modules.
 |
 |
vhdl t -file dp32.vhdl
This command creates a parse tree t. When an error is encountered during parsing, the constructor fails and no parse tree is created. In this case an error message is returned as the result of the command. The root node of this tree can be retrieved by issuing the method root to the parse tree:
set root [t root]
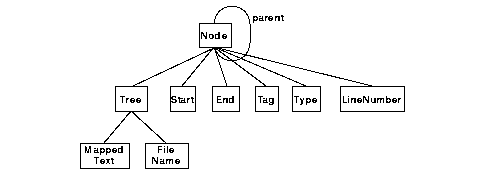
This command assigns the identifier of the tree root to the Tcl variable root. Nodes have three data members visible from the extension language: type, tag, and text. Type contains an enumeration value that encodes the rule from which this node was created. The domain of this enumeration is defined by the tree to which a particular node belongs. For example, the code 24 is assigned to nodes of type architecture, created by the vhdl parser. The code 24 corresponds to node type block_configuration for nodes created by the config parser. Tag contains the tag from a grammar symbol if any was defined. For example, the config parser assigns the tag entityName to the node created for the third identifier of architecture_body nodes. Finally, text contains the text region between the start and end offsets stored for a particular node. For the root node of a parse tree, this is always the complete input.
rule traversal {
node:IDENTIFIER "all" list { qualifier }
"-var" var:IDENTIFIER code_block
| node:IDENTIFIER "one" list { qualifier }
}
rule qualifier {
"-type" type:IDENTIFIER
| "-tag" tag:IDENTIFIER
}
The first variant executes a Tcl code block for every node, optionally considering only those nodes with selected type and tag in the tree rooted at node. The node currently looked at is available in the variable named var within the code block. The code block may contain break and continue statements to break out of the traversal completely or to continue with a sibling of the current node. The second variant traverses the tree rooted at node and breaks at the first node of type node:IDENTIFIER or fails if no such node exists.
The method on tree nodes that implements these commands realizes the following algorithm:
| in | set<tags> | tags to be matched against node tag |
| in | set<types> | types to be matched against node type |
| in | variable name | Tcl variable to which to assign the node identifier currently processed |
| in | action code | Tcl code to evaluate for a node with matching tag and type |
| in | one | one or all command |
| out | success/failure | return code resulting from evaluating the action code |
if (node type and node tag match inputs) {
set Tcl variables for current node type,
current node tag, and current node text
set Tcl variable named by parameter to current node identifier
evaluate action code passed as input
if (return code from action evaluation == OK) {
if (one) {
return BREAK;
} else {
return (return code from action evaluation);
}
}
if (node type is list or node has children) {
for each list element or child {
traverse recursively,
passing input tags and types, variable name,
action code and one flag
switch (return code from recursive invocation) {
case OK or CONTINUE:
break:
case BREAK:
return BREAK;
case RETURN:
if (node type is list) {
insert returned node identifier at current list position
} else {
replace current child with returned node identifier
}
break;
default:
return (return code from recursive invocation);
}
}
}
Node::traverse effectively performs a preorder tree traversal, checking each node visited for matching tag and type. If a matching node is encountered, some Tcl variables are set to establish the execution context for the action code, and the action code is evaluated. Depending on the return code of this evaluation, traversal either continues with the children or list elements of the matching node, or breaks off completely and continues with the next sibling of the matching node. By issuing appropriate break, continue, and return statements within the action code, and by recursively calling traversal commands from within the action code, the programmer is given fine control over the exact tree traversal. In the Section 6.7, we will see that this flexibility is in fact needed when we show in detail how to transform VHDL configuration declarations into DIM object graphs.
The following extension language command is defined:
rule unparse {
module:IDENTIFIER "::unparse" "-rule" rule:IDENTIFIER
list { "-" IDENTIFIER "{" parameter_value "}" }
}
rule parameter_value {
"-text" LITERAL
| "-code" tcl_code
| "-node" node:IDENTIFIER
| "-list" tcl_code
}
An unparse command is invoked for a specific rule. Tree node creation is controlled by a keyword that specifies a parameter to be either
rule block_configuration {
"for" implName:IDENTIFIER
list { use_clause }
items:repeat { configuration_item }
"end" "for" ";"
}
A sequence of extension language commands that writes a block configuration to standard output would be
set tree [config::unparse -rule block_configuration
-implName { -code $parent_DesignObject Name }
-items { -list set ComponentConfigurations } ]
$tree export stdout
The unparse function defined in the config parse module is invoked. The implementation name is found by evaluating the method Name on the object stored in variable parent_DesignObject. Component configurations are filled in by evaluating the unparse methods on all the objects stored in the variable ComponentConfigurations. Note that no parameter has to be given for the list of use_clauses as this list may have zero or more elements.
VHDL provides a good case study of our specification language for the following reasons:
The primary design abstraction in VHDL is the design entity. An entity declaration defines the interface between a given design entity and the system in which it is used. An architecture body specifies the implementation of a design entity in terms of the relationships between its inputs and outputs. There may be multiple architecture bodies defined for a given entity declaration. The selection of a specific implementation for a design entity is handled by configuration declarations.
Concurrent statements are used in architecture bodies to define interconnected blocks and processes that jointly describe the overall behaviour or structure of a design. Concurrent statements come in various forms, notably block statements to group other concurrent statements and process statements which represent single independent sequential processes. Other concurrent statements exist for commonly occurring forms of processes as well as for representing structural decomposition and regular descriptions.
VHDL provides a rich type system encompassing scalar, composite, access, and file types much like ADA. Subprograms may be used to define algorithms. Object types provided are constants, signals, and variables. Objects may be associated with predefined or user-defined attributes. Object and subprogram definitions may be grouped into packages, realizing an abstract data type. Entity, configuration and package declarations as well as architecture and package bodies may be independently analysed and inserted into a design library.
syntax vhdl {
token comment -ignore -pattern <"--" .* $>
token ID -pattern <[_a-zA-Z0-9]+>
token USE -pattern <"use" [^;]* ";">
token LIBRARY -pattern <"library" [^;]* ";">
token END -pattern <"end" [^;]* ";">
rule design_file { repeat { toplevel } }
rule toplevel { LIBRARY | USE | entity | architecture | package | config }
} // syntax vhdl
A design file contains at least one top-level design unit. In addition, there may be directives to include external libraries and selected objects from these libraries into the scope of the design file. Most of the detail specified in the top-level design units can safely be ignored for design information management. Their names are important, however.
rule entity { "entity" Name:ID <\n> guts <\n> END }
rule architecture { "architecture" Name:ID ID EntityName:ID guts END }
rule package { "package" guts END }
rule guts { list { item | ID } }
In the rule for entities we have included export directives (the two patterns "<\n>") to show their use. The rule guts collectively describes all the internals of design units.
While we completely ignore special characters (remember that the generated scanner is instructed to read over all text for which it has no explicit pattern), certain keywords and identifiers have to be distinguished to find component declarations.
rule item {
"procedure" guts END
| "function" guts END
| "units" guts END
| "record" guts END
| "block" guts END
| "generate" guts END
| "process" guts END
| "case" guts END
| "if" guts END
| "loop" guts END
| USE
| component
}
rule component { "component" Name:ID guts END }
Although the granularity at which the top-level specification module is written is sufficient to locate design units and extract their names, it is too coarse to analyse configuration declarations. In fact, we need all the details from a configuration declaration, so the specification module for configurations is written at a very fine granularity. Configuration declarations are introduced with the keyword configuration, so a rule with this single keyword as right-hand-side provides a suitable anchor for invoking the config specification:
rule config -syntax { "configuration" }
Structural implementations can declare a component specification and create instances of components. A component thus declared can be thought of as a template for a design entity. The binding of an entity to this template is achieved through a configuration declaration. The declaration can also be used to specify actual generic constants for components and blocks. So the configuration declaration plays a pivotal role in organizing a design description in preparation for simulation or other processing.
The declarative part of a configuration declaration allows the configuration to use items from libraries and packages. The outermost block configuration in the configuration declaration defines the configuration for an architecture of the named entity.
syntax config {
token comment -ignore -pattern <"--" .* $>
token IDENTIFIER -pattern <[_a-zA-Z] [_a-zA-Z0-9]*>
rule configuration_declaration {
"configuration" configName:IDENTIFIER
"of" interfaceName:IDENTIFIER "is"
list { use_clause } block_configuration
"end" opt { IDENTIFIER } ";"
}
} // syntax config
Note that a nested specification module is completely self-contained. We have to specify a fresh set of comment conventions, tokens, keywords, and special characters for each module we define.
Within the block configuration for an architecture, the submodules of the architecture may be configured. These submodules include blocks and component instances. A block is configured with a nested block configuration. Where a sub-module is an instance of a component, a component configuration is used to bind an entity to the component instance. Note the extensive use of tags on rule items. We will see shortly how these are used in both import and export specifications.
rule block_configuration {
"for" implName:IDENTIFIER
list { use_clause }
items:list { configuration_item }
"end" "for" ";"
}
rule configuration_item {
block_configuration
| component_configuration
}
rule component_configuration {
"for" component_specification
binding:opt { "use" binding_indication ";" }
block:opt { block_configuration }
"end" "for" ";"
}
rule component_specification {
instantiation_list ":" componentName:IDENTIFIER
}
rule instantiation_list {
repeat -separator "," { instanceName:IDENTIFIER }
| "others"
| "all"
}
rule binding_indication {
entity_aspect
opt { "generic" "map" association_list }
opt { "port" "map" association_list }
}
rule entity_aspect {
"entity" "work." childInterfaceName:IDENTIFIER
opt { "(" childImplName:IDENTIFIER ")" }
| "configuration" "work." childConfigName:IDENTIFIER
| "open"
}
rule use_clause { "use" ";" }
rule association_list { "(" ")" }
We assume that the node identifier of the tree root has been assigned to variable tree by the following statement
set tree [[vhdl T -file dp32.vhdl] root]
$tree all -type configuration_declaration -var n1 {
$n1 one -tag configName -type IDENTIFIER {
set configName $text }
$n1 one -tag interfaceName -type IDENTIFIER {
set interfaceName $text }
$n1 one -type block_configuration n2 {
doBlockConfig \
$n2 $interfaceName $interfaceName $configName
}
}
This top-level loop finds all nodes of type configuration_declaration, extracts the configuration name and the name of the associated interface from them, and processes the single block configuration contained in them by calling the procedure doBlockConfig. Configuration declarations always contain a single block configuration which configures an architecture body. The other two one-statements identify the individual identifiers found in a configuration declaration by checking their tags and exploiting the fact that the text of a matching node can be directly accessed through the text variable from within the action code. No node identifiers are required.
The procedure doBlockConfig has the following code:
| in | n1 | identifier of a block configuration |
| in | path | list of objects that represent the current nesting level |
| in | interfaceName | name of the interface of this block |
| in | configurationName | name of the outermost configuration declaration |
| out | configuration identifier | the identifier of the block configuration created |
proc doBlockConfig {n1 path interfaceName configName} {
$n1 one -tag implName -type IDENTIFIER { set implName $text }
$n1 all -type component_configuration -var n2 {
$n2 one -tag componentName -type IDENTIFIER {
set componentName $text }
$n2 one -type entity_aspect -var n3 {
$n3 one -tag childInterfaceName -type IDENTIFIER {
set childInterfaceName $text
}
set childImplName ""
catch { $n3 one -tag childImplName -type IDENTIFIER {
set childImplName .$text
}}
}
catch(6) { unset CC }
$n2 all -type block_configuration -var n3 {
set nestedC [doBlockConfig
$n3 $path.$implName
$childInterfaceName $configName]
if {$childImplName != ""} {
# check whether the block configuration just created
# is for childImpl
$n3 one -tag implName -type IDENTIFIER {
set nestedImplName $text }
if {"$childImplName" == ".$nestedImplName"} {
# create a component configuration
# that points to the block configuration
set CC [ComponentConfiguration #auto
-Name
"cc:$path.$implName.$componentName"
-Configuration $C
-Component
$interfaceName.$implName.$componentName
-Child $nestedC]
}
}
}
if [catch { set CC }] {
# no nested block configuration has configured the childImpl
# create a component configuration
# that points to the childimpl directly
set CC [ComponentConfiguration #auto
-Name "cc:$path.$implName.$componentName"
-Configuration $C
-Component
$interfaceName.$implName.$componentName
-Child $childInterfaceName$childImplName]
}
# don't search for component_configuration's
# in nested block_configuration's
continue
}
return $C
}
Here, the parameters for the creation of a component configuration are simplified in that components are referenced by their path name instead of a DIM object identifier retrieved by a query operation. In brief, the purpose of procedure doBlockConfig is to resolve a single, possibly nested block configuration statement. It mainly consists of a big loop over all component configurations. The continue statement at the end of the loop prevents the traversal from implicitly diving into nested block configurations because these are to be handled explicitly. For each component configuration, a check is made whether a corresponding block configuration exists. If so, this block configuration is recursively resolved and used as child design object for the component configuration. If no such block configuration exists, the named implementation is used as child design object for the component configuration. The net result of letting this code operate on the parse tree created from a configuration in the DP32 processor is the object graph depicted in Figure 14 on page 76.
| DIM type | unparse method |
|---|---|
| Configuration |
return [config::unparse -rule block_configuration
-implName { -code [$this Implementation] Name }
-items { -list set ComponentConfigurations } ]
|
| ComponentConfiguration |
switch [$Child info class] {
Implementation {
return [config::unparse -rule component_configuration
-component_specification { -code
concat "all:" [$Component Name] }
-binding { -code
concat "use entity" [$Child Name] } ]
}
Configuration {
return [config::unparse -rule component_configuration
-component_specification { -code
concat "all:" [$Component Name] }
-binding { -code
concat "use entity"
[[[$this Implementation] Interface] Name] }
"(" [[$this Implementation] Name] ")"
-block { -node $Child unparse } ]
}}
|
For a configuration, an enclosing VHDL configuration_declaration has to be created first (we assume the variable C to contain the DIM object identifier of the configuration to be exported):
[config::unparse -rule configuration_declaration
-name { -code $C Name } -entityRef { -code [$C Interface] Name }
-block_configuration { -node $C unparse } ] export $VHDLfile
Table 11 shows the unparse methods for the types Configuration and ComponentConfiguration in our conceptual schema. Every configuration visited is emitted as a nested block configuration in the VHDL file. Depending on whether the child design object of a component configuration is an implementation or a configuration, the respective VHDL binding indication is emitted.
The Nelsis CAD Framework [Dimes 93b] supports tool integration on a number of different levels, with a set of interface functions that allow to access design data at varying granularities:
| granularity | interface functions |
|---|---|
| file-based | dmGetPathOfStream, dmMoveFileToStream, dmCloseStream |
| stream-based | dmOpenStream, dmGetDesignData, dmPutDesignData, dmCloseStream |
| value-based | dmOpenStream, dmGetDesignData, dmPutDesignData, dmCloseStream |
While Nelsis, too, does not provide a toolkit to write language processors for arbitrary design description languages, it offers an extensible set of format handlers for common formats. A format handler is a library function that knows how to read and write design data in a specific format. The functions dmGetDesignData and dmPutDesignData take the format handler needed to process a particular design description language as a parameter. Format handlers provide a uniform interface to design data from a tool's point of view. Unfortunately, support to write new format handlers is restricted to scanf/printf-like functions. This is clearly insufficient for free-format languages like VHDL.
Regarding the problem of framework support for design description languages to find an answer to the question "how to map between syntax and objects," some solutions are offered in the literature. Many "C++" class libraries have methods to dump an object graph to a file and to read such files back into memory. However, the format of such a dump is fixed, whereas the object-oriented database system OBST follows a more flexible approach. Its Structurer and Flattener (STF, [Pergande 93]) is a general tool to map between textual files and objects stored in an OBST database. STF translates a single syntax specification into a pair of programs, a structurer to read an object graph from a file, and a flattener to write an object graph to a file (the generation process is similar to the one depicted in Figure 25). The structurer contains a yacc-generated parser, the flattener is constructed from a set of recursive procedures. While the STF approach resembles ours, it can not be applied for the following reasons:
Graver describes the system T-gen to automatically generate string-to-object translators in the context of the Smalltalk programming environment [Graver 93]. T-gen supports a large class of grammars (LL(1), SLR(1), LALR(1), LR(1)). The generated translators are Smalltalk objects and either create two variants of parse trees, derivation trees or abstract syntax trees from their input. While derivation trees contain all intermediate non-terminals created during parsing, abstract syntax trees are pruned by parse-tree builder directives (PTBs) inserted in the syntax specification by the programmer. PTBs can be used to explicitly construct a parse tree node or to control the flow of information between tree nodes. For example, there is a PTB liftRightChild to help flattening the derivation tree. Consider a set of rules of the form(7)
ArgList : Arg ArgList { liftRightChild }
| Arg { ArgumentListNode };
Arg : <argument> { ArgumentNode };
The capitalized PTBs ArgumentNode and ArgumentListNode create tree nodes. The PTB liftRightChild prevents that a new tree node is created. Instead, the tree associated with the right-most symbol on the right-hand side is used as tree for the symbol on the left-hand side. The other right-hand side symbols are appended as children to this tree, thus effectively flattening the derivation tree to a list. Our system could benefit from the introduction of PTBs. However, because we skip large parts of an input file, the parse trees generated by our parsers are generally small. By means of our declarative operators all and one we create the illusion of a pruned tree that only contains relevant information for the programmer. This approach has the advantages that we can keep the syntax specification completely free of manually inserted action code. All "tree pruning" is done from extension language scripts.
Certainly, there are more sophisticated systems to process parse trees, yet all of them insist on processing files down to single lexems, as, after all, this is required for compiler construction. They also have limitations which make them unusable as general toolkits for building language processors to encapsulate design tools. Txl [Carmichael 92] relies on its own internal representation of parse trees and provides no documented hooks to extract information from such trees. Puma [Grosch 91] uses Modula2 as implementation language and relies on the use of its associated compiler frontend. A viable alternative to our parse tree operators might have been the use of Sorcerer [Parr 94], but we prefer a solution using an interpreted language in which framework administrators or even designers can easily create new or modify existing mappings without the need for recompilation.
[Table of Contents] |
[5. Design information management] |
[Top of Chapter] |
[7. Case Study: Design system for high-level synthesis] |