[Table of Contents] |
[2. Integration] |
[4. Tool encapsulation architecture] |
[Table of Contents] |
[2. Integration] |
[4. Tool encapsulation architecture] |
In terms of database technology, an information model abstracts from the fine-grained detail of an actual implementation. To be of any value, the information model must be based on some well-defined formalism.
Early attempts to define data models stem from the area of database design. The first data models (hierarchical and network data models) directly described the physical data organization supported by a database management system (DBMS) and provided only low-level operations for data manipulations. The relational model is based on the formally defined relational theory and effectively insulates the user of a DBMS from the physical data organization. It provides, however, only scalar datatypes (boolean, integer, real, string) and flat relations as datatypes and therefore is not well suited to model technical domains.
A data model that allows to capture more semantics is the entity-relationship (ER) model by Chen [Chen 76]. This model represents information in terms of entities and the relationships between them. A major advantage of the ER model is that a graphical notation is defined for it which is the usual technique to capture ER models. Since its introduction, many extensions have been proposed to make it more suitable for the modelling of technical systems like electronic circuits. Of these, especially aggregation and generalization are of importance ([Smith 77], [Batory 85]).
With the more widely spread acceptance of the object-oriented concepts and the quest for a richer type system the EXPRESS language, now an ISO proposed standard [Spiby 93], has gained wider acceptance. EXPRESS is an object-oriented language used for information modelling. It comes with a graphical notation (EXPRESS-G) that provides graphical idioms for a subset of the textual EXPRESS language. EXPRESS-G diagrams share a major disadvantage with ER diagrams in that they are unordered. No natural entry point into the diagram can guide the reader in understanding such a diagram. More important, depending on the entry point chosen by a reader, an ER or EXPRESS-G diagram can mean different things.
We have chosen the Xplain semantic data model [terBekke 92] over the other approaches for its few and well-defined concepts and clear graphical notation (Figure 6).
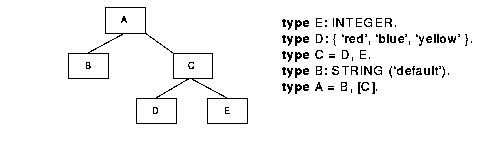 |
The key concept in Xplain is a type:
In addition, Xplain allows to specialize an aggregate type by adding new attributes to an existing type. For example, Table 7 shows the type extents of the types shown in Figure 6.
| type | extent |
|---|---|
| A | { (b,d,e) | b B, d D, e E } |
| B | { e Strings } |
| C | { (d,e) | d D, e E } |
| D | { 'red','blue',yellow' } |
| E | { e RealNumber } |
Xplain defines two inherent integrity rules for the types in an information model [terBekke 93]:
The syntax specification language allows to define both lexical properties and syntax in a single specification file. While at this point this is merely a matter of convenience, it will become essential when using the language to capture input and output syntaxes in a single specification. Simple keywords can be directly placed into the grammar as symbols. Token classes have to be defined before their use by means of regular expressions.
The following keywords are defined:
-export, -ignore, -left, -nonassoc, -pattern, -prec, -right,
-separator, -syntax, -type, list, opt, prec, range, repeat,
rule, syntax, token
These are the token definitions for the specification language:
token LINE_COMMENT -ignore <"//" .* $>
token BRACKETED_COMMENT -ignore <"/*" .* "*/">
token ID -pattern <[_A-Za-z] [_A-Za-z0-9]*>
token PATTERN -pattern <"<" [^>]+ ">">
token LITERAL -pattern <\" ( [^"\\] | \\[nt\\"] )* \">
rule word {
| "opt" alternatives
| "list" separator alternatives
| "repeat" separator alternatives
}
rule separator {
opt { "-separator" LITERAL }
}
Lists may define a separator literal like "," or ";". All EBNF constructs can be replaced with non-extended constructs.
rule opt { /**/ | alternatives }
rule list { /**/ | list alternatives }
rule sep_list { /**/ | tmp }
rule tmp { alternatives | tmp separator:LITERAL alternatives }
rule repeat { alternatives | repeat alternatives }
rule sep_repeat {
alternatives | sep_repeat separator:LITERAL alternatives
}
syntax meta_spec {
rule modules {
repeat { "syntax" ID "{" list { token | prec } repeat { rule } "}" }
}
} // syntax meta_spec
rule token {
"token" ID opt { "-ignore" } "-pattern" PATTERN
}
Symbol precedence and associativity may be defined by a number of precedence statements, each with a list of literals or grammar symbols. Precedence and associativity are used in the generated parser to resolve grammar ambiguities. The earlier precedence statements list the literals and grammar symbols with low precedence. The later a precedence statement appears, the higher the precedence of its literals and grammar symbols.
rule prec {
"prec" prec_property list { ID | LITERAL }
}
rule prec_property {
"-left" | "-right" | "-nonassoc" | /**/
}
rule rule {
"rule" ID alternatives
}
rule alternatives {
"{" list -separator "|" { words } "}"
}
A word may either be
rule words {
list { opt { ID ":" } word } opt { "-prec" ID }
}
rule word {
PATTERN
| ID | LITERAL
| "opt" alternatives
| "list" separator alternatives
| "repeat" separator alternatives
| alternatives
}
rule separator {
opt { "-separator" LITERAL }
}
The syntax specification language as presented in this section will be extended by some specific constructs to enhance its usability as specification language for design file processors in Section 6.4 on page 111. There, we will also look into how efficient design file processors can be generated mostly automatically from such a specification.
[Table of Contents] |
[2. Integration] |
[Top of Chapter] |
[4. Tool encapsulation architecture] |